Group work with Alex MacNamara and Michael Cusack-Nelkin
-
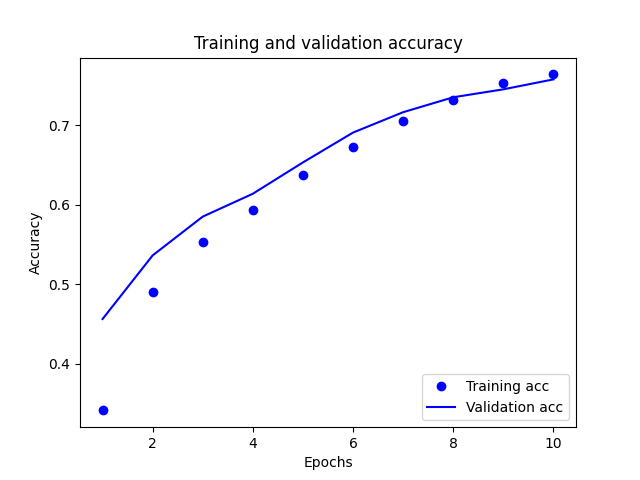
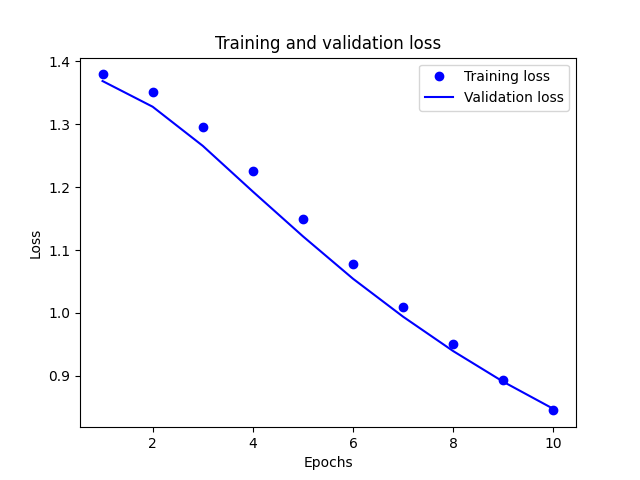
The model’s accuracy ended up around 0.73, and the validation data is performing slightly better than the training data.
-
The test data accuracy was also around 0.73. While not perfect, the test data does seem to validate our model
- [0.49240538, 0.44442952, 0.56419706, 0.49765235],
- Predicts the example to be Javascript, but the actual label is Java (incorrect)
[0.49345428, 0.4782082 , 0.47585246, 0.5415826 ],
- Predicts the example to be python, and the actual label is python (correct)
[0.5465847 , 0.458411 , 0.53137875, 0.45516586]
- Predicts the example to be c#, and the actual label is c# (correct)
The model seems to be assigning independent probabilities?
- One of the significant differences between the binary and the multi-class was the last layer of the model because it went from having two output classes to having four. Also, when looking at the plots comparing training and validation accuracy and loss, the binary model shows better training scores while the multi-class model exhibits better validation scores. The binary model got better results, as the accuracy for the binary model was around 0.87 while the stack_overflow test accuracy was 0.73.
{kind=link}
{kind=link}